January 3, 2018
Durante esta semana, estuve leyendo mas acerca del libro de Writing Great Code, por lo que ahora continue con el capítulo 5, el cual habla sobre la representación de caracteres. Durante la lectura te vas adentrando demasiado a como es que funcionan los caracteres y cual es su propósito.
Ademas de que puede ampliar tu panorama, entendiendo un poco sobre las ventajas y desventajas que puedes encontrar al utilizar los distintos tipos de caracteres.
Pero para plantearnos ¿Como es que funcionan los caracteres?, primero debimo habernos preguntado:
¿Qué es un carácter?
Un carácter es cualquier símbolo que tu puedes escribir en el teclado de tu computadora y se puede visualizar en el display.
Character Data
Existen distintos tipos de estándares que nos permiten la representación de caracteres, de entre los cuales los mas famosos son:
- ASCII
- EBCDI
- UNICODE
ASCII ( American Standard Code for Information Interchange)
Este estándar cuenta con un total de 128 caracteres sin signo del 0 al 127 ($0 .. $7F) pero este se puede extender 128 caracteres mas, llegando a los 256 caracteres ($80 .. $FF).
Estos caracteres se dividen en 4 grupos, los cuales son:
Grupo 1 - Caracteres de control ($0 .. $1F)
Estos caracteres permiten la comunicación con las entradas y salidas de un un sistema, como lo podría ser la interacción con una impresora por dar un ejemplo.
Grupo 2 - Símbolos de puntuación y números
Son los caracteres especiales como el espacio, ademas de los dígitos numéricos los cuales son representados del $30 .. $39. Grupo 3 - Abecedario en mayúsculas. ($41 .. $5A)
Grupo 3 - Abecedario en mayúsculas.
Este conjunto representa los 26 caracteres del alfabeto (A a la Z en mayúscula), también dentro del conjunto se encuentran 6 símbolos especiales.
Grupo 4 - Abecedario en minúsculas.
Esta dividido casi de la misma manera que el anterior, solo que se diferencia en vez de 6 símbolos especiales son 5 símbolos y 1 dedicado para el borrado o eliminación.
De forma mas vizual veremos la diferencia entre un caracter del alfabeto del grupo 3 y grupo 4.
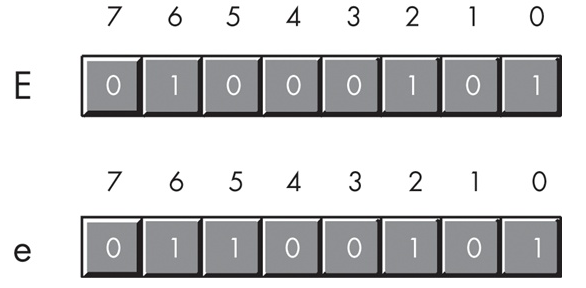
ASCII garantiza la compatibilidad entre sistemas debido a que podría ser el más ocupado en la actualidad.
Extended Binary Decimal Interchange Code ( EBCDI )
EBCDI es un conjunto de caracteres que tiene un núcleo en común. un ejemplo de ello es que los caracteres alfabéticos existe en distintas versiones del EBCDI que también contiene codificaciones de los signos de puntuación. Otro de los datos interesantes es que dicho estándar es usado en los mainframes y mini computadores de IBM, ademas de que es una extension del BCDIC.
Double-Byte Characters
Este estándar surgió ante la necesidad de representar mas de 256 caracteres,por lo que usa un byte para representar la mayoría de sus caracteres y 2 bytes para representar ciertos caracteres.
Los caracteres típicos se encuentran en un rango del $80 .. $FF. Algunos de ellos indican que un segundo byte sigue inmediatamente, esto significa que por cada byte extra se obtiene una extension de 256 caracteres mas. Por otra parte Double-Byte Characters puede representar hasta 1021 caracteres. Pero no todo es miel sobre hojuelas, debido a que también tiene sus problemas:
- Es complicado trabajar con el
- Para conocer que carácter ocupa 2 bytes se tiene que recorrer toda la cadena
UNICODE
Es el estándar internacional adoptado para mostrar mas de 256 caracteres a la vez. UNICODE usa una palabra de 16-bit para representar cada carácter, por lo tanto acepta hasta 65,536 códigos de carácter diferente. UNICODE es compatible con ASCII. Actualmente es ocupado por Windows internamente ayudando a eficiente sus procesos del Sistema Operativo.
Desventajas:
- Los datos requieren el doble de memoria para ser representados a comparación del ASCII.
- La mayoría de los datos del mundo ocupan ASCII o EBCDIC por lo que se puede perder mucho a la hora de realizar conversiones.
Character String formats
Existen distintos tipos de formatos de cadenas de caracteres, pero dentro de ellas hay diferencias, como el que algunas permiten menor uso de memoria, otros permiten acelerar el procesamiento, mientras algunos son mas maniobrables y por último, algunos agregan mayor funcionalidad a la hora de programar.
Entre estos tipos estan los siguientes:
Zero-Terminated Strings
Esta es la representación mas común strings, ya que es la muestra nativa en C, C++ y Java. La secuencia de este formato esta distribuida de tal forma que cuenta con 0 o más caracteres de 8-bit (1 byte cada carácter) seguido de un byte 0.
Ventajas:
- Puede representar cadenas de cualquier longitud con un byte e sobrecarga.
- Disponibilidad para distintos lenguajes de programación debido a su popularidad.
- Fácil de implementar y representación.
Desventajas:
- No son muy eficientes en terminación cero debido a que es necesario conocer la longitud de la cadena, lo que provoca un escaneo de la cadena de inicio a fin alentando su funcionamiento.
- No se puede representar ningún carácter cuyo valor sea 0 (Ejemplo : NUL o NULL).
- La concatenación puede extender la longitud de una variable provocando desbordamiento.
Lengh-Prefix Strings
Es muy común en el lenguaje Pascal, consiste en 1 byte que especifica la longitud seguido de los demás bytes generados por la cadena, por ejemplo:
“abc” = 1 byte de la longitud + 3 bytes por cada carácter, dando un total de 4 bytes
Ventajas:
- Resuelve problemas de las cadenas en terminación cero, como la representación del carácter nulo agregando mayor eficiencia.
- Soluciona el problema de longitud, mostrando esta en la posición 0 de la cadena.
Desventajas:
- Esta limitada a un conjunto máximo de 255 caracteres, se pierde uno debido al byte ocupado para la longitud.
- Puede dar solución al problema anterior agregando de 2 a 4 bytes pero causando otro problema que afecta directamente al almacenamiento en la memoria.
Seven-Bit Strings
Este formato consiste en usar el bit HO para indicar el fin de una cadena, esto sucede debido a que el único bit establecido en este tipo de cadena es el HO. Este formato es muy ocupado en el Leguaje Ensamblador.
Ventajas:
- No requiere un byte extra o de sobrecarga para codificar la longitud
Desventajas:
- Escaneo de toda la cadena para determinar la longitud.
- No puede tener cadenas de longitud cero.
- Pocos lenguajes usan este formato.
- Limitado a un máximo de 128 caracteres
HLA
El HLA combina las ventajas de Lengh-Prefix Strings y Zero-Terminated Strings a costa de la sobrecarga en la cadena. Pero esto afecta directamente en el uso de la memoria, si es que llegara a existir una restricción en ella. El formato HLA esta compuesto de la siguiente forma:

Prefijo (4 bytes) -> Permite que los caracteres tenga la posibilidad de más de 4 mil millones de caracteres.
Bit-0 (1 byte) -> Terminación de la cadena con un bit 0
Longitud (4 bytes) -> Permite saber la longitud de la cadena.
Longitud Máxima (4 bytes) -> Determina la longitud máxima que puede alcanzar la cadena en caso de que exista algún cambio.
Types of Strings
Static
Son aquellos cuyo tamaño máximo es elegido por el programador, por ejemplo:
char String[26] -> Se asigna una longitud de 26 caracteres.
Pseudo-Dynamic String
Funciona de forma similar al formato HLA, en donde el sistema establece la longitud en tiempo de ejecución, asignando automáticamente la memoria que se va a necesitar
Dynamic
Son aquellas a las cuales se les asigna el almacenamiento suficiente de acuerdo a la cadena sin importar que esta se ajuste o cambie.
Lo malo de este tipo es que se puede recolectar basura ocasionada por los cambios que se realicen a la longitud del string.
Character Sets
Un conjunto de caracteres esta conformado por un conjunto matemático de caracteres los cuales permiten realizar operaciones de acuerdo al tipo de carácter

Existen muchas formas de representar un conjunto de cadenas, una de ellas es a través de valores booleanos para determinar si un carácter pertenece a un conjunto de caracteres, en donde:
true = El carácter pertenece al conjunto de caracteres.
false = El carácter no pertenece al conjunto de caracteres.
Otro de los puntos importantes es que se asigna un bit para cada carácter en un conjunto de caracteres, por lo tanto un conjunto consiste en 128 bites (16 bytes).
Si un conjunto de datos es muy pequeño la manera de representarlos es a través de una cadena de caracteres.
Pero si un conjunto de dato es muy grande entonces la mejor manera de representarlos es por medio de una lista de conjunto de caracteres.
La verdad es que todo lo mencionado anteriormente es de suma importancia a la hora de escribir código, ya que como programador no tomamos en cuenta las consecuencias que pueden pasar o el como es que funcionan los caracteres, ya que parece algo normal en nuestro día a día a la hora de teclear código.
Si llegaras a no estar de acuerdo con algún punto de vista en la reseña con gusto me puedes contactar como @onahump en twitter y github.